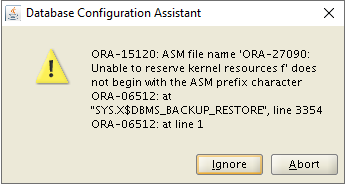
Problem:
In a mixed environment when you have 19c GI, but several versions of Oracle RDBMS home (19c, 12c), initially during 12c database restore you may encounter the following error:
ORA-15001: diskgroup "DATA" does not exist or is not mounted
ORA-15040: diskgroup is incomplete
There are several reasons for the above error and one of them is when the $ORACLE_HOME/bin/oracle binary under rdbms home does not have group asmadmin. After identifying it, you try to change permissions to oracle:asmadmin and but after a while, you may notice that the group is reset to oinstall. It can happen after patching or after running relink manually. So let’s see test case:
[oracle@rac1 lib]$ ll /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
-rwsr-s--x 1 oracle asmadmin 323613256 Feb 19 17:00 /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
Run relink:
[oracle@rac1 lib]$ make -f ins_rdbms.mk ioracle
Check permissions again:
[oracle@rac1 lib]$ ll /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
-rwsr-s--x 1 oracle oinstall 323613256 Feb 19 17:03 /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
If you do the same for 19c home, group is still asmadmin.
Reason:
ins_rdbms.mk script is different in 19c and 12c, comparing ioracle section:
12c:
ioracle: preinstall $(ORACLE)
-$(NOT_EXIST) $(ORACLE_HOME)/bin/oracle ||\
mv -f $(ORACLE_HOME)/bin/oracle $(ORACLE_HOME)/bin/oracleO
-mv $(ORACLE_HOME)/rdbms/lib/oracle $(ORACLE_HOME)/bin/oracle
-chmod 6751 $(ORACLE_HOME)/bin/oracle
19c:
ioracle: preinstall $(ORACLE)
-$(RMF) $(ORACLE_HOME)/bin/oracle
-mv $(ORACLE_HOME)/rdbms/lib/oracle $(ORACLE_HOME)/bin/oracle
-chmod 6751 $(ORACLE_HOME)/bin/oracle
-(if [ ! -f $(ORACLE_HOME)/bin/crsd.bin ]; then \
getcrshome="$(ORACLE_HOME)/srvm/admin/getcrshome" ; \
if [ -f "$$getcrshome" ]; then \
crshome="`$$getcrshome`"; \
if [ -n "$$crshome" ]; then \
if [ $$crshome != $(ORACLE_HOME) ]; then \
oracle="$(ORACLE_HOME)/bin/oracle"; \
$$crshome/bin/setasmgidwrap oracle_binary_path=$$oracle; \
fi \
fi \
fi \
fi\
);
As you see ioracle section in 12c does not contain the last IF statement which sets oracle binary group to asmadmin (using setasmgidwrap)
Solution:
Unfortunately, I cannot recommend adding that if statement in 12c ins_rdbms.mk although I did it in my test environment and works as expected.
After running make -f ins_rdbms.mk ioracle for 12c the group is set to asmadmin.
It is better to ask Oracle about this change and do only after you get an approval from them.
The only non-harmful recommendation from my side would be to have permission change script and run after every patch or relink:
# chown oracle:asmadmin /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
# chmod 6751 /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
# ll /u01/app/oracle/product/12.1.0/dbhome_1/bin/oracle
If you still decide to add IF statement as I did, please make sure there is TAB instead of spaces before IF clause. Otherwise, you will get the following error and you can easily understand which line should be corrected.
[oracle@rac1 lib]$ make -f ins_rdbms.mk ioracle
ins_rdbms.mk:120: *** missing separator (did you mean TAB instead of 8 spaces?). Stop.