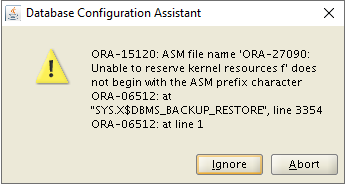
Problem:
CRS on the 1st node is able to start, but not on the 2nd node.
CRS on the 2nd node hangs and later fails:
CRS-2672: Attempting to start 'ora.storage' on 'rac2'
ORA-01017: invalid username/password; logon denied
CRS-5055: unable to connect to an ASM instance because no ASM instance is running in the cluster
during that time CRS alert.log shows:
2022-03-15 20:15:23.722 [ORAROOTAGENT(63477)]CRS-5019: All OCR locations are on ASM disk groups [GRID], and none of these disk groups are mounted. Details are at "(:CLSN00140:)" in "/u01/app/grid/diag/crs/rac2/crs/trace/ohasd_orarootagent_root.trc".
ohasd_orarootagent_root.trc shows:
2022-03-15 20:23:35.108 : USRTHRD:1769867008: [ INFO] {0:5:3} [ora.storage] 9788 Error 4 querying length of attr ASM_DISCOVERY_ADDRESS
2022-03-15 20:23:35.110 : USRTHRD:1769867008: [ INFO] {0:5:3} [ora.storage] 9788 Error 4 querying length of attr ASM_STATIC_DISCOVERY_ADDRESS
2022-03-15 20:23:35.136 : USRTHRD:1769867008: [ INFO] {0:5:3} [ora.storage] 9506 Error 4 opening dom root in 0x7fa3100013a0
Reason:
Either the password file is corrupted or it does not exist. In our case, GRID diskgroup was created after clearing disk headers and forgot to copy ASM password file.
Solution:
- If you have ASM password file backup, then you can simply place it to the asm diskgroup:
$ asmcmd pwcopy --asm /tmp/asm_passwordfile +GRID/orapwASM -f
and stop/start CRS.
2. If you don’t have password file backup, you need to create a new one and add necessary users into it:
[grid@rac1 ~]$ asmcmd pwcreate --asm +GRID/orapwasm -f
Enter password: **********
Check existing users:
[grid@rac1 ~]$ asmcmd lspwusr
Username sysdba sysoper sysasm
SYS TRUE TRUE FALSE
Add necessary users and grant permissions:
$ asmcmd orapwusr --grant sysasm SYS
$ asmcmd orapwusr --add ASMSNMP
Enter password: *********
$ asmcmd orapwusr --grant sysdba ASMSNMP
Check permissions again:
$ asmcmd lspwusr
Username sysdba sysoper sysasm
SYS TRUE TRUE TRUE
ASMSNMP TRUE FALSE FALSE
Find out the user name and password for CRSD to connect, GI uses internal user CRSUSER__ASM_001 with an internally generated password to access ASM during startup:
Find the string SYSTEM.ASM.CREDENTIALS.USERS.CRSUSER__ASM_001 in the following output and save. ORATEXT value:
# ocrdump -stdout | less
...
[SYSTEM.ASM.CREDENTIALS.USERS.CRSUSER__ASM_001]
ORATEXT : d68aec9585136fa8ff8f79f483e4ae64:grid
SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS, GROUP_PERMISSION : PROCR_READ, OTHER_PERMISSION : PROCR_NONE, USER_NAME : grid, GROUP_NAME : oinstall}
Query password for GUID-user. GUID will be different in your case. Retrieve value from your output:
# crsctl get credmaint -path /ASM/Self/d68aec9585136fa8ff8f79f483e4ae64 -credtype userpass -id 0 -attr passwd -local
mB28wSM4AVFAVEYamUIvrMjEo2Nfa
Add this user to ASM password file:
$ asmcmd orapwusr --add CRSUSER__ASM_001
>>>>> provide <password> you retrieved earlier
Add necessary credentials to this user:
$ asmcmd orapwusr --grant sysdba CRSUSER__ASM_001
$ asmcmd orapwusr --grant sysasm CRSUSER__ASM_001
Check the list again:
$ asmcmd lspwusr
Username sysdba sysoper sysasm
SYS TRUE TRUE TRUE
ASMSNMP TRUE FALSE FALSE
CRSUSER__ASM_001 TRUE FALSE TRUE
Stop/Start CRS on the remaining node.