Pre-requisites:
- Install Oracle Enterprise Linux 6.5
Recommendations:
a) After installing OS it is better to install oracle-rdbms-server-11gR2-preinstall-1.0-7.el6.x86_64.rpm from installation cd. It will prepare the environment for future database installation.
b) Turn off selinux.
c) Set static ip instead of DHCP.
- Install Oracle 11.2.0.3 software and create database named ORCL.
Steps described in this post:
- Install Oracle 11.2.0.4 software only.
- Upgrade ORCL database using DBUA(located in 11.2.0.4)
- Download latest Opatch version for 11.2.
- Using Oracle Recommended Patch Advisor download
Patch 23054359 – Database Patch Set Update 11.2.0.4.160719 (Includes CPUJul2016) and apply it to newly upgraded database.
Let’s start:
- Install Oracle 11.2.0.4 software only using silent installation method:
a) Download 11.2.0.4 software from here: p13390677_112040_Linux-x86-64_1of7.zip and p13390677_112040_Linux-x86-64_2of7.zip or from metalink.
b) Make necessary directories to save installation files and unzip files there:
mkdir /0
cd /0
mkdir 11.2.0.4
cd 11.2.0.4
Place zip files in /0/11.2.0.4/
unzip p13390677_112040_Linux-x86-64_1of7.zip
unzip p13390677_112040_Linux-x86-64_2of7.zip
c) Prepare the response file located in /0/11.2.0.4/database/response/db_install.rsp
Just change the following entries:
#—————————————————————–
# Specify the installation option.
# It can be one of the following:
# – INSTALL_DB_SWONLY
# – INSTALL_DB_AND_CONFIG
# – UPGRADE_DB
#—————————————————————–
oracle.install.option=INSTALL_DB_SWONLY
#—————————————————————–
# Specify the hostname of the system as set during the install. It can be used
# to force the installation to use an alternative hostname rather than using the
# first hostname found on the system. (e.g., for systems with multiple hostnames
# and network interfaces)
#—————————————————————–
ORACLE_HOSTNAME=oracle01
#—————————————————————–
# Specify the Unix group to be set for the inventory directory.
#—————————————————————–
UNIX_GROUP_NAME=oinstall
#—————————————————————–
# Specify the location which holds the inventory files.
# This is an optional parameter if installing on
# Windows based Operating System.
#—————————————————————–
INVENTORY_LOCATION=/u01/app/oraInventory
SELECTED_LANGUAGES=en
#—————————————————————–
# Specify the complete path of the Oracle Home.
#—————————————————————–
ORACLE_HOME=/u01/app/oracle/product/11.2.0.4
#—————————————————————–
# Specify the complete path of the Oracle Base.
#—————————————————————–
ORACLE_BASE=/u01/app/oracle
# Specify the installation edition of the component.
# The value should contain only one of these choices.
# – EE : Enterprise Edition
# – SE : Standard Edition
# – SEONE : Standard Edition One
# – PE : Personal Edition (WINDOWS ONLY)
#—————————————————————–
oracle.install.db.InstallEdition=EE
#—————————————————————–
# The DBA_GROUP is the OS group which is to be granted OSDBA privileges.
#—————————————————————–
oracle.install.db.DBA_GROUP=dba
#—————————————————————–
# The OPER_GROUP is the OS group which is to be granted OSOPER privileges.
# The value to be specified for OSOPER group is optional.
#—————————————————————–
oracle.install.db.OPER_GROUP=dba
#—————————————————————–# Specify the auto-updates option. It can be one of the following:
# – MYORACLESUPPORT_DOWNLOAD
# – OFFLINE_UPDATES
# – SKIP_UPDATES
#—————————————————————–
oracle.installer.autoupdates.option=SKIP_UPDATES
#—————————————————————–
# Specify whether to enable the user to set the password for
# My Oracle Support credentials. The value can be either true or false.
# If left blank it will be assumed to be false.
#
# Example : SECURITY_UPDATES_VIA_MYORACLESUPPORT=true
#—————————————————————–
SECURITY_UPDATES_VIA_MYORACLESUPPORT=false
#—————————————————————–
# Specify whether user doesn’t want to configure Security Updates.
# The value for this variable should be true if you don’t want to configure
# Security Updates, false otherwise.
#
# The value can be either true or false. If left blank it will be assumed
# to be false.
#
# Example : DECLINE_SECURITY_UPDATES=false
#—————————————————————–
DECLINE_SECURITY_UPDATES=true
d) Switch to oracle user(this user is created when you install oracle-rdbms-server-11gR2-preinstall-1.0-7.el6.x86_64.rpm)
su – oracle
cd /0/11.2.0.4/database
./runInstaller -silent -responseFile /0/11.2.0.4/database/response/db_install.rsp -showProgress
Run root scrips as indicated at the end of the installation.
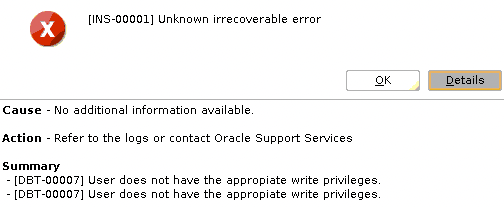
Note: If you are getting the following error after executing runInstaller:
[FATAL] [INS-35172] Target database memory (1500MB) exceeds the systems available shared memory ({0}MB).
CAUSE: The total available shared memory on the system (1496 MB) was less than the chosen target database memory (1500 MB).
ACTION: Enter a value for target database memory that is less than 1496 MB.
In parameter file there was described MEMORY_TARGET parameter to 1500MB but /dev/shm size was not big enough. You should increase the size for /dev/shm (the same as tmpfs).
su –
vi /etc/fstab
Add option size=10G accross the line tmpfs.
tmpfs /dev/shm tmpfs defaults,size=10G 0 0
Remount tmpfs to make the changes take effect without restarting server.
mount -o remount tmpfs
2. Upgrade ORCL database using DBUA(located in 11.2.0.4)
Note database should be started from old home of course.
a) Set the environment variables using oraenv
[oracle@oracle01 ~]$ . oraenv
ORACLE_SID = [oracle] ? orcl
The Oracle base has been set to /u01/app/oracle
b) Run dbua from 11.2.0.4 home. Indicate sid of the database to be upgraded and oracle home of the database to be upgraded : /u01/app/oracle/product/11.2.0.3
[oracle@oracle01 bin]$ /u01/app/oracle/product/11.2.0.4/bin/dbua -silent -sid orcl -oracleHome /u01/app/oracle/product/11.2.0.3 -diagnosticDest /u01/app/oracle
Log files for the upgrade operation are located at: /u01/app/oracle/cfgtoollogs/dbua/orcl/upgrade1
Performing Pre Upgrade
1% complete
7% complete
Upgrading Oracle Server
7% complete
8% complete
9% complete
10% complete
10% complete
11% complete
12% complete
12% complete
13% complete
14% complete
15% complete
15% complete
16% complete
17% complete
17% complete
18% complete
19% complete
20% complete
20% complete
21% complete
22% complete
Upgrading JServer JAVA Virtual Machine
23% complete
24% complete
Upgrading Oracle XDK for Java
25% complete
26% complete
Upgrading OLAP Analytic Workspace
27% complete
Upgrading OLAP Catalog
29% complete
Upgrading EM Repository
30% complete
31% complete
32% complete
32% complete
33% complete
34% complete
35% complete
35% complete
36% complete
37% complete
37% complete
38% complete
39% complete
40% complete
40% complete
41% complete
42% complete
42% complete
Upgrading Oracle Text
44% complete
Upgrading Oracle XML Database
45% complete
46% complete
47% complete
47% complete
48% complete
49% complete
50% complete
50% complete
51% complete
52% complete
52% complete
53% complete
54% complete
55% complete
55% complete
56% complete
57% complete
Upgrading Oracle Java Packages
58% complete
Upgrading Oracle interMedia
60% complete
60% complete
Upgrading Spatial
62% complete
62% complete
Upgrading Oracle Workspace Manager
64% complete
Upgrading Expression Filter
65% complete
66% complete
67% complete
67% complete
68% complete
69% complete
70% complete
70% complete
71% complete
72% complete
72% complete
73% complete
74% complete
75% complete
Upgrading Rule Manager
76% complete
Upgrading Oracle Application Express
77% complete
Upgrading Oracle OLAP API
78% complete
Performing Post Upgrade
79% complete
80% complete
85% complete
Configuring Database with Enterprise Manager
86% complete
87% complete
92% complete
Generating Summary
Database upgrade has been completed successfully, and the database is ready to use.
100% complete
Check the log file “/u01/app/oracle/cfgtoollogs/dbua/logs/silent.log” for upgrade details.
c) Check the status of the listener, it should be stopped from the old home and started from new home.
[oracle@oracle01 bin]$ lsnrctl status
Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521))
STATUS of the LISTENER
————————
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.3.0 – Production
Start Date 25-AUG-2016 17:55:13
Uptime 0 days 1 hr. 30 min. 18 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/app/oracle/product/11.2.0.3/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/oracle01/listener/alert/log.xml
Listening Endpoints Summary…
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=oracle01)(PORT=1521)))
Services Summary…
Service “orcl” has 1 instance(s).
Instance “orcl”, status READY, has 1 handler(s) for this service…
Service “orclXDB” has 1 instance(s).
Instance “orcl”, status READY, has 1 handler(s) for this service…
The command completed successfully
[oracle@oracle01 bin]$ lsnrctl stop
Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521))
The command completed successfully
[oracle@oracle01 bin]$ cp /u01/app/oracle/product/11.2.0.3/network/admin/listener.ora /u01/app/oracle/product/11.2.0.4/network/admin/listener.ora
[oracle@oracle01 bin]$ cp /u01/app/oracle/product/11.2.0.3/network/admin/tnsnames.ora /u01/app/oracle/product/11.2.0.4/network/admin/tnsnames.ora
##########################Reset oracle environment variables to take new home.
[oracle@oracle01 ~]$ . oraenv
ORACLE_SID = [oracle] ? orcl
The Oracle base has been set to /u01/app/oracle
[oracle@oracle01 bin]$ lsnrctl start
Starting /u01/app/oracle/product/11.2.0.4/bin/tnslsnr: please wait…
TNSLSNR for Linux: Version 11.2.0.4.0 – Production
System parameter file is /u01/app/oracle/product/11.2.0.4/network/admin/listener.ora
Log messages written to /u01/app/oracle/diag/tnslsnr/oracle01/listener/alert/log.xml
Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=oracle01)(PORT=1521)))
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521)))
STATUS of the LISTENER
————————
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.4.0 – Production
Start Date 25-AUG-2016 19:27:45
Uptime 0 days 0 hr. 0 min. 0 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/app/oracle/product/11.2.0.4/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/oracle01/listener/alert/log.xml
Listening Endpoints Summary…
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=oracle01)(PORT=1521)))
The listener supports no services
The command completed successfully
[oracle@oracle01 bin]$ lsnrctl status
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521)))
STATUS of the LISTENER
————————
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.4.0 – Production
Start Date 25-AUG-2016 19:27:45
Uptime 0 days 0 hr. 0 min. 21 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/app/oracle/product/11.2.0.4/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/oracle01/listener/alert/log.xml
Listening Endpoints Summary…
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=oracle01)(PORT=1521)))
Services Summary…
Service “orcl” has 1 instance(s).
Instance “orcl”, status READY, has 1 handler(s) for this service…
Service “orclXDB” has 1 instance(s).
Instance “orcl”, status READY, has 1 handler(s) for this service…
The command completed successfully
Note: If you have been using static registration of the database in listener.ora file. Then you must change ORACLE_HOME parameter there to indicate new home.
d) Let’s check that the version was changed:
[oracle@oracle01 bin]$ cat /etc/oratab
# This file is used by ORACLE utilities. It is created by root.sh
# and updated by either Database Configuration Assistant while creating
# a database or ASM Configuration Assistant while creating ASM instance.
# A colon, ‘:’, is used as the field terminator. A new line terminates
# the entry. Lines beginning with a pound sign, ‘#’, are comments.
#
# Entries are of the form:
# $ORACLE_SID:$ORACLE_HOME:<N|Y>:
#
# The first and second fields are the system identifier and home
# directory of the database respectively. The third filed indicates
# to the dbstart utility that the database should , “Y”, or should not,
# “N”, be brought up at system boot time.
#
# Multiple entries with the same $ORACLE_SID are not allowed.
#
#
orcl:/u01/app/oracle/product/11.2.0.4:N
[oracle@oracle01 bin]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Thu Aug 25 19:29:01 2016
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 – 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> select instance_name,version,status from v$instance;
INSTANCE_NAME VERSION STATUS
—————- —————– ————
orcl 11.2.0.4.0 OPEN
SQL> select count(*) from dba_objects where status=’INVALID’;
COUNT(*)
———-
0
exit
3. Download latest Opatch version for 11.2.
On metalink you can find the latest opatch from the following documet.
Patch – Where Can I Find the Latest Version of OPatch(6880880)? [Video] (Doc ID 224346.1)
Choose Release OPatch 11.2.0.0.0
Platform Linux x86-64
Downloaded file name is p6880880_112000_Linux-x86-64.zip
Or you can download from my drive p6880880_112000_Linux-x86-64.zip
Unzip downloaded file and place OPatch folder in 11.2.0.4 home directory. For this you will need to delete or rename existing OPatch folder.
mv /u01/app/oracle/product/11.2.0.4/OPatch /u01/app/oracle/product/11.2.0.4/OPatch_backup
cp -R /0/patch/OPatch /u01/app/oracle/product/11.2.0.4/OPatch
########## Describe this folder in PATH variable to make your work easy
export PATH=$PATH:/u01/app/oracle/product/11.2.0.4/OPatch
4. Using Oracle Recommended Patch Adviser download
Patch 23054359 – Database Patch Set Update 11.2.0.4.160719 (Includes CPUJul2016) and apply it to newly upgraded database.
Or download from my drive p23054359_112040_Linux-x86-64.zip
Open readme.html and follow the instuctions.
a) Stop database
[oracle@oracle01 ~]$ sqlplus / as sysdba
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
b) Stop listener
[oracle@oracle01 ~]$ lsnrctl stop
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521)))
The command completed successfully
c) Stop Enterprise manager
[oracle@oracle01 ~]$ emctl stop dbconsole
Oracle Enterprise Manager 11g Database Control Release 11.2.0.4.0
Copyright (c) 1996, 2013 Oracle Corporation. All rights reserved.
https://oracle01:1158/em/console/aboutApplication
Stopping Oracle Enterprise Manager 11g Database Control …
… Stopped.
d) Unzip downloaded file and go to the directory named 23054359
cd /0
mkdir patch
#############Place p23054359_112040_Linux-x86-64.zip here
unzip p23054359_112040_Linux-x86-64.zip
cd 23054359
e) Apply the patch(Note we have already described path /u01/app/oracle/product/11.2.0.4/OPatch in PATH variable, that is why writing just opatch command is enough)
[oracle@oracle01 23054359]$ opatch apply
Oracle Home : /u01/app/oracle/product/11.2.0.4
Central Inventory : /u01/app/oraInventory
from : /u01/app/oracle/product/11.2.0.4/oraInst.loc
OPatch version : 11.2.0.3.14
OUI version : 11.2.0.4.0
Log file location : /u01/app/oracle/product/11.2.0.4/cfgtoollogs/opatch/opatch2016-08-25_20-13-27PM_1.log
Verifying environment and performing prerequisite checks…
OPatch continues with these patches: 17478514 18031668 18522509 19121551 19769489 20299013 20760982 21352635 21948347 22502456 23054359
Do you want to proceed? [y|n]
y
User Responded with: Y
All checks passed.
Provide your email address to be informed of security issues, install and
initiate Oracle Configuration Manager. Easier for you if you use your My
Oracle Support Email address/User Name.
Visit http://www.oracle.com/support/policies.html for details.
Email address/User Name:
You have not provided an email address for notification of security issues.
Do you wish to remain uninformed of security issues ([Y]es, [N]o) [N]: y
Please shutdown Oracle instances running out of this ORACLE_HOME on the local system.
(Oracle Home = ‘/u01/app/oracle/product/11.2.0.4’)
Is the local system ready for patching? [y|n]
y
User Responded with: Y
Backing up files…
Applying sub-patch ‘17478514’ to OH ‘/u01/app/oracle/product/11.2.0.4’
Patching component oracle.rdbms, 11.2.0.4.0…
Patching component oracle.rdbms.rsf, 11.2.0.4.0…
Patching component oracle.sdo, 11.2.0.4.0…
Patching component oracle.sysman.agent, 10.2.0.4.5…
Patching component oracle.xdk, 11.2.0.4.0…
Patching component oracle.rdbms.dbscripts, 11.2.0.4.0…
Patching component oracle.sdo.locator, 11.2.0.4.0…
Patching component oracle.nlsrtl.rsf, 11.2.0.4.0…
Patching component oracle.xdk.rsf, 11.2.0.4.0…
Patching component oracle.rdbms.rman, 11.2.0.4.0…
Applying sub-patch ‘18031668’ to OH ‘/u01/app/oracle/product/11.2.0.4’
Patching component oracle.rdbms, 11.2.0.4.0…
Patching component oracle.rdbms.rsf, 11.2.0.4.0…
Patching component oracle.ldap.rsf, 11.2.0.4.0…
Patching component oracle.rdbms.crs, 11.2.0.4.0…
Patching component oracle.precomp.common, 11.2.0.4.0…
Patching component oracle.ldap.rsf.ic, 11.2.0.4.0…
Patching component oracle.rdbms.deconfig, 11.2.0.4.0…
Patching component oracle.rdbms.dbscripts, 11.2.0.4.0…
Patching component oracle.rdbms.rman, 11.2.0.4.0…
Applying sub-patch ‘18522509’ to OH ‘/u01/app/oracle/product/11.2.0.4’
Patching component oracle.rdbms.rsf, 11.2.0.4.0…
Patching component oracle.rdbms, 11.2.0.4.0…
Patching component oracle.precomp.common, 11.2.0.4.0…
Patching component oracle.rdbms.rman, 11.2.0.4.0…
Patching component oracle.rdbms.dbscripts, 11.2.0.4.0…
Patching component oracle.rdbms.deconfig, 11.2.0.4.0…
Applying sub-patch ‘19121551’ to OH ‘/u01/app/oracle/product/11.2.0.4’
Patching component oracle.precomp.common, 11.2.0.4.0…
Patching component oracle.sysman.console.db, 11.2.0.4.0…
Patching component oracle.rdbms.rsf, 11.2.0.4.0…
Patching component oracle.rdbms.rman, 11.2.0.4.0…
Patching component oracle.rdbms, 11.2.0.4.0…
…….
Note: In “Email address/User Name:” I have just pressed the enter.
If you have questions please ask.
Thanks to Giorgi Peikrishvili for this case also 🙂