Azure: Get email when VM instance state changes
January 20, 2022 Leave a comment
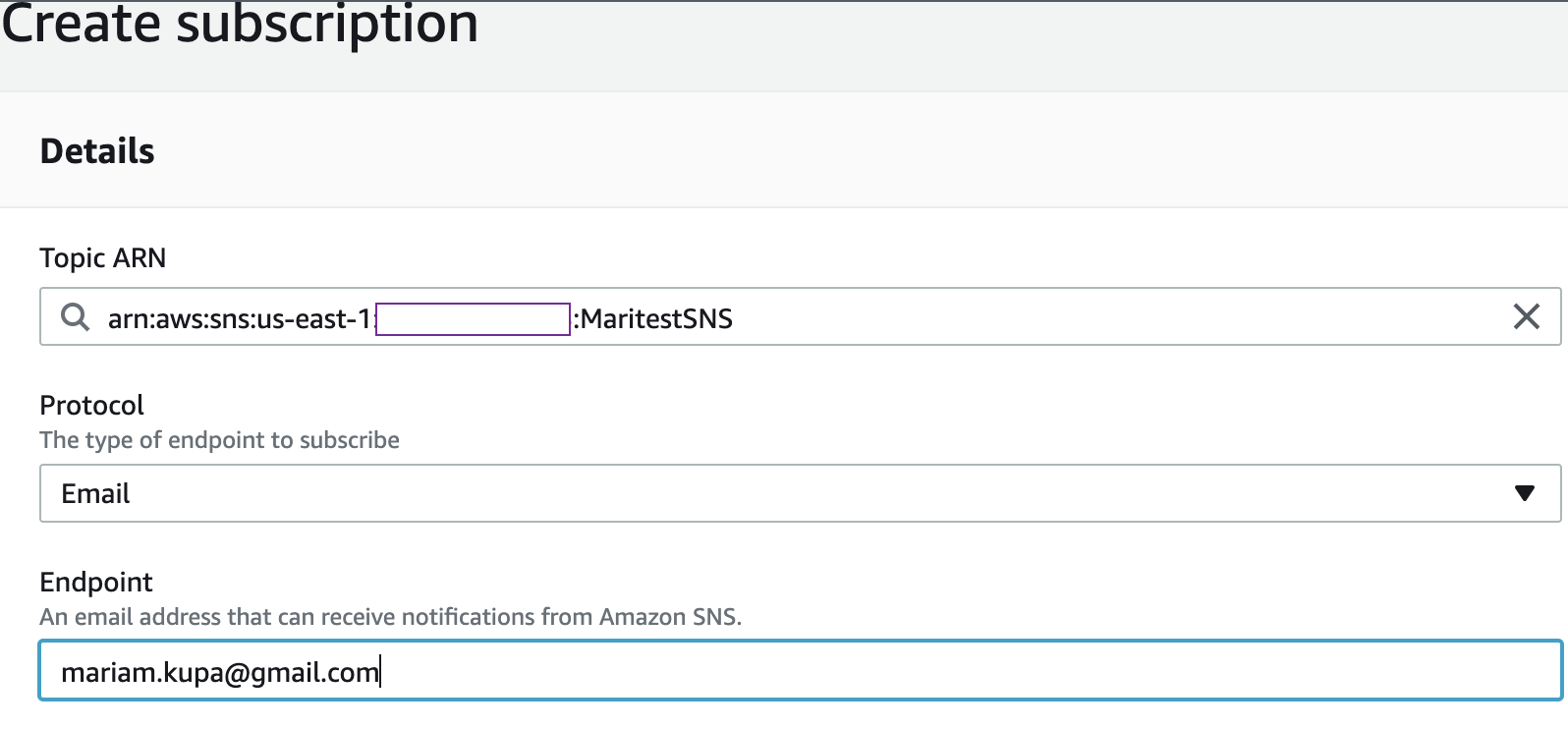
To set up email notification in Azure environment when VM changes the state, you should do the following:
1. In the Azure portal, select Service Health

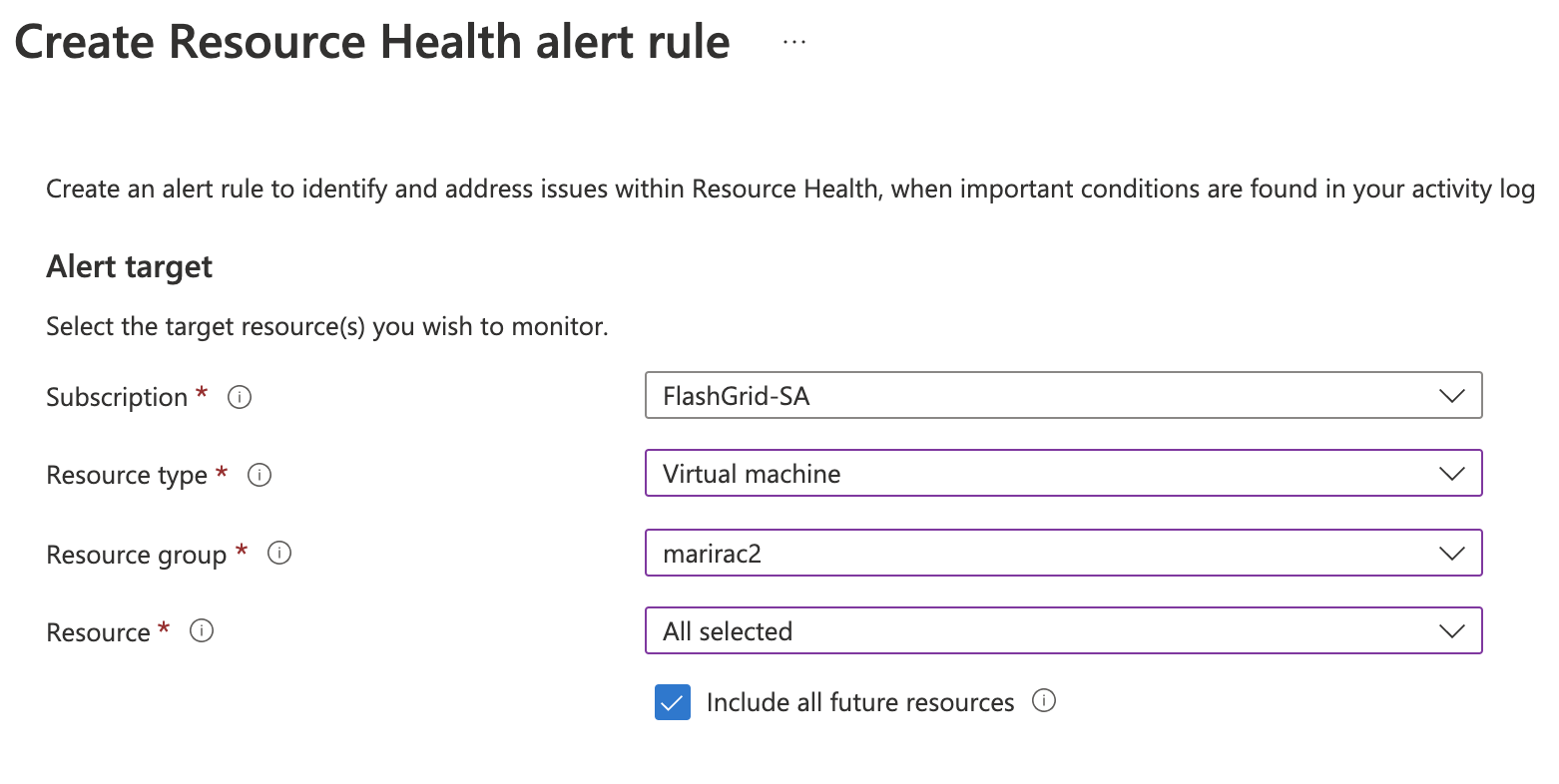
2. From the left side panel choose Resource health -> click Create Resource Health alert rule
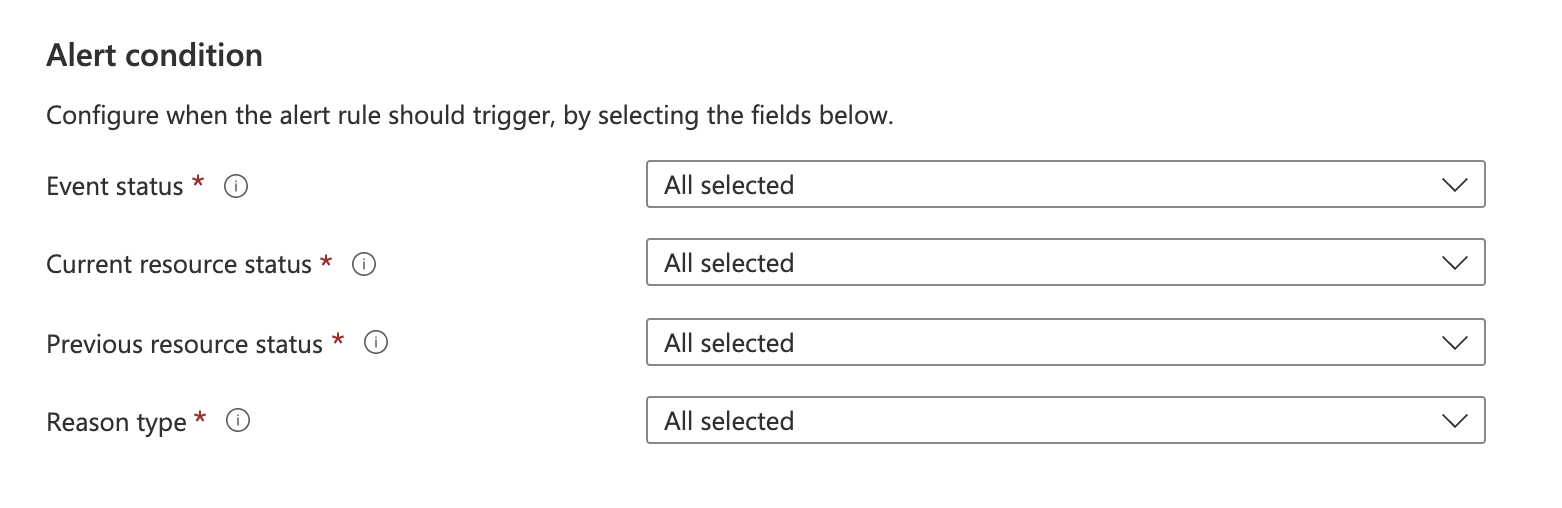
Fill in the necessary fields:
In the Actions section, you have to indicate action groups. As long as we have not created any before, let’s click Add action groups -> Create action group

And fill in the following fields:
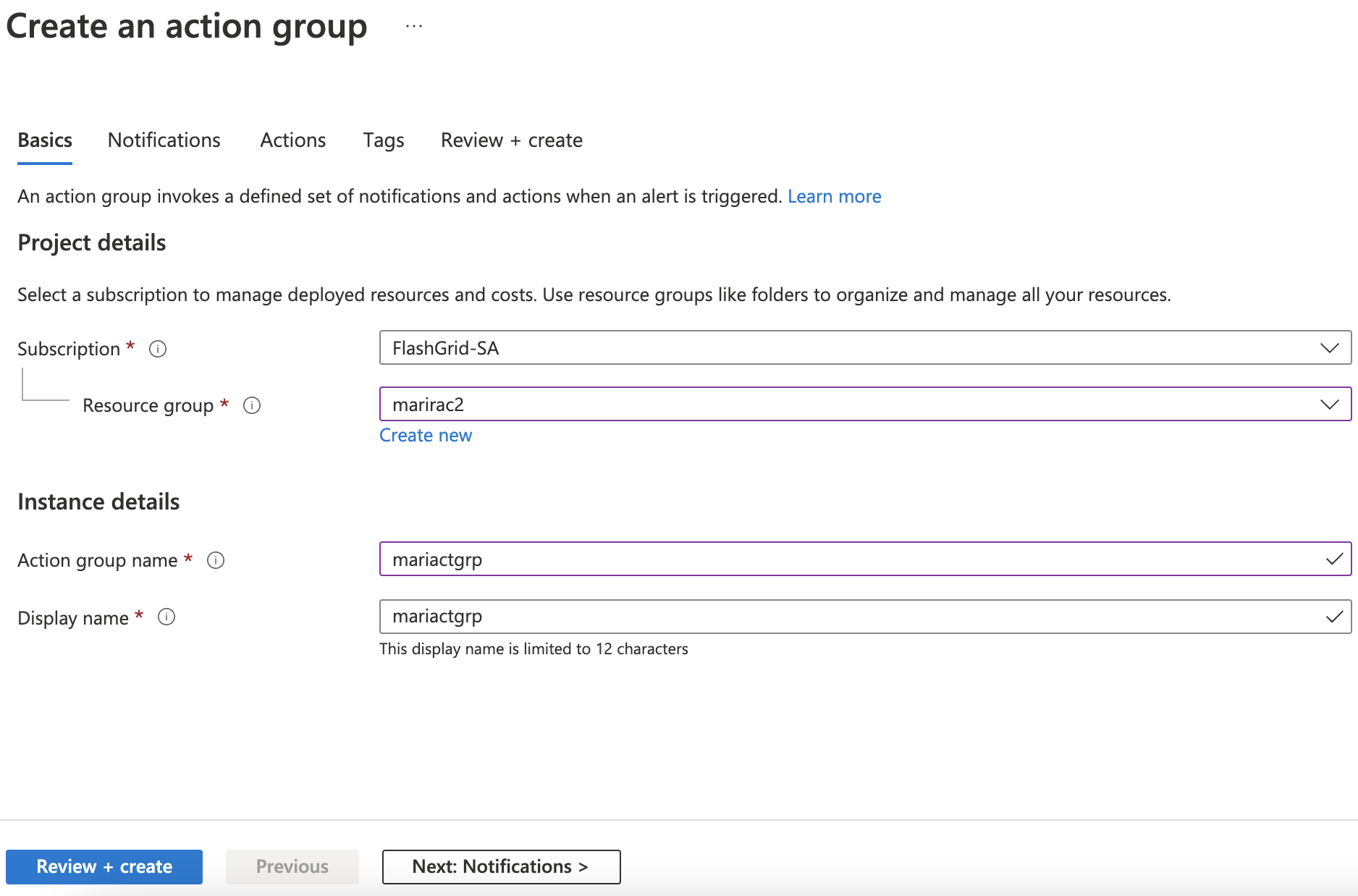
Click Review + create -> Create.
After creating the group you will see that the new group was chosen automatically. Fill in fields under Alert rule details:
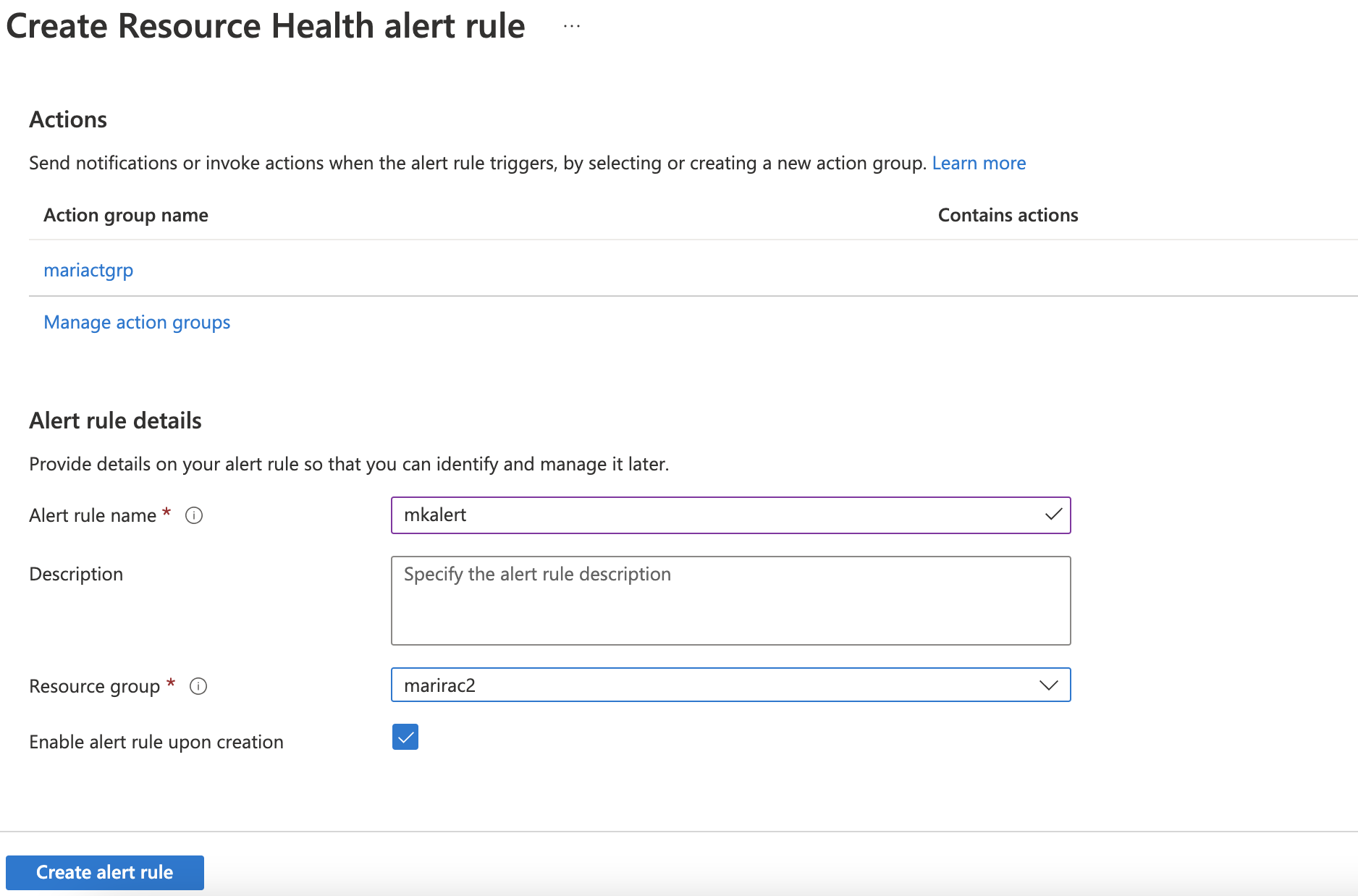
Click Create alert rule.
3. Go to the Resource Group (in my case marirac2) where you have created Action Group.
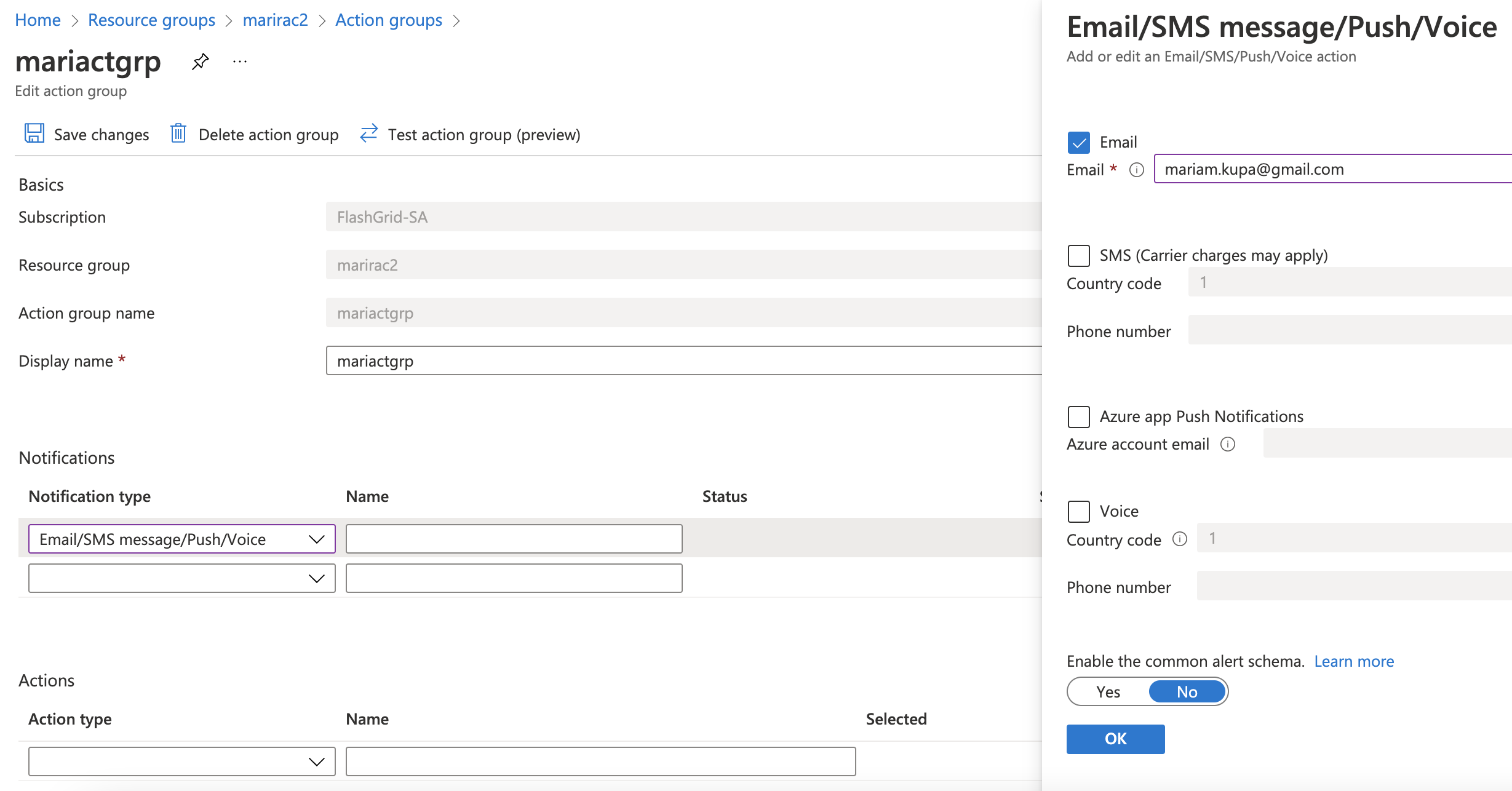
Resource groups -> marirac2 -> from the left-side panel choose Alerts -> Action groups -> choose action group name in my case mariactgrp -> on the Notifications section choose Email/SMS message/Push/Voice -> on the right-side panel click Email checkbox -> enter email address who will be responsible for receiving and handling these alerts -> click OK -> enter desirable name under Notifications section -> click Save changes.
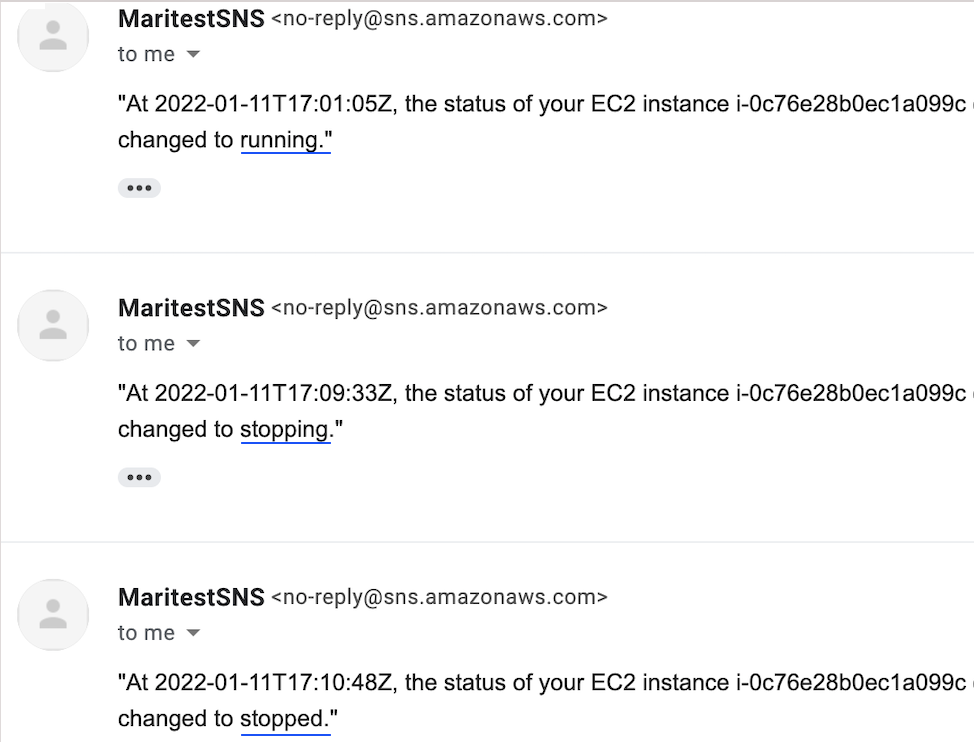
4. Test alert by stopping and starting the VM (assuming it is a test environment)
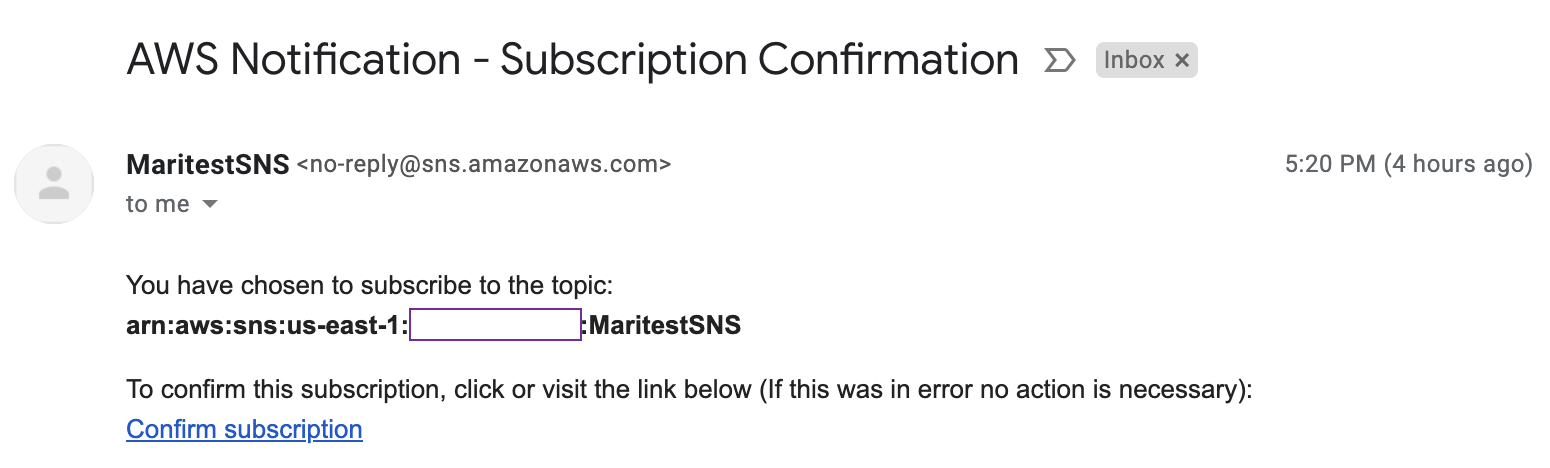
After changing the state of the VM you will receive the following notification.
Please note notification should have been sent as soon as VM changes the state but email can come 2 – 3 min later.