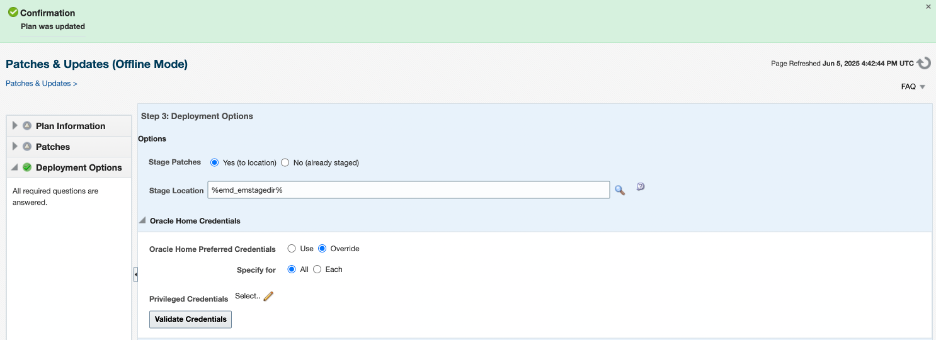
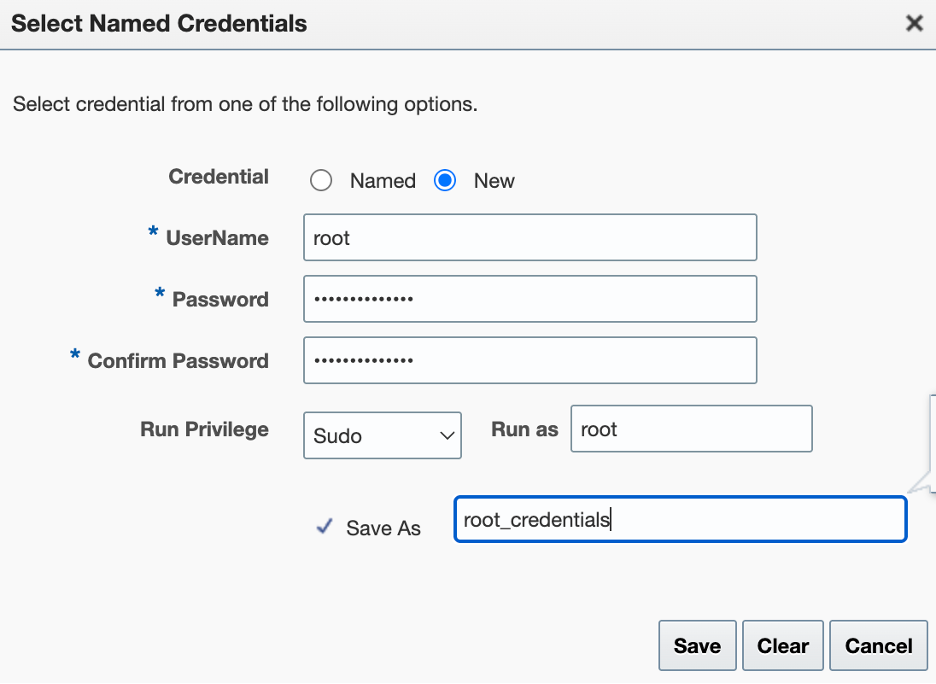
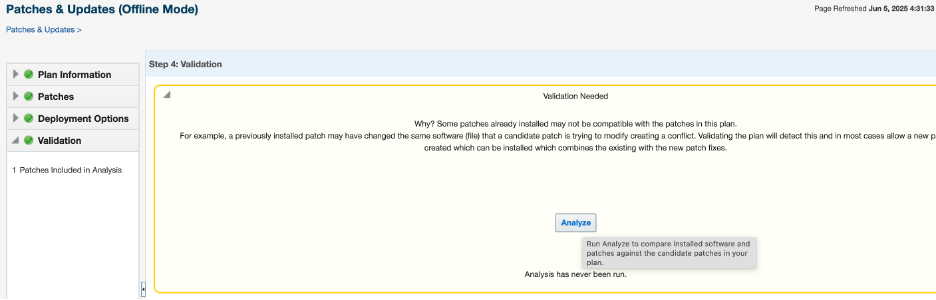
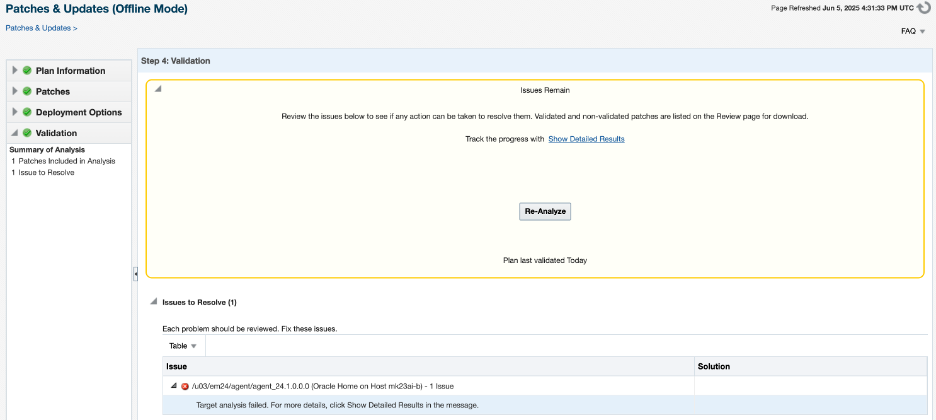
The blog may appear extensive, but most of the content consists of the output from the command. The reason for including the output is to allow for comparison.
1. Ensure that you have OMSPatcher version 13.9.24.4.0
$ $ORACLE_HOME/OMSPatcher/omspatcher version
If the version returned is lower than that, which it most likely is, then you need to update OMSPatcher in the OMS home.
To update OMSPatcher, please follow the steps outlined below:
1.1. Download patch 19999993 for EM 24.1.0.0.0 (for your version) from My Oracle Support
1.2. Backup the current “OMSPatcher” folder
$ mv <MIDDLEWARE_HOME>/OMSPatcher <MIDDLEWARE_HOME>/OMSPatcher_backup
For example:
$ mv /u03/em24/middleware/oms_home/OMSPatcher /u03/em24/middleware/oms_home/OMSPatcher_backup
1.3. Unzip the “p19999993_241000_Generic.zip” under /u03/em24/middleware/oms_home
$ unzip /u03/install/p19999993_241000_Generic.zip -d /u03/em24/middleware/oms_home
1.4. Check the version again and make sure the version is correct
$ export ORACLE_HOME=/u03/em24/middleware/oms_home
$ $ORACLE_HOME/OMSPatcher/omspatcher version
OMSPatcher Version: 13.9.24.4.0
OPlan Version: 12.2.0.1.16
OsysModel build: Tue Apr 28 18:16:31 PDT 2020
2. Analyze the patch before actual application to ensure that all prerequisites are met:
$ /u03/em24/middleware/oms_home/OMSPatcher/omspatcher apply -analyze 37629905/
OMSPatcher Automation Tool
Copyright (c) 2024, Oracle Corporation. All rights reserved.
OMSPatcher version : 13.9.24.4.0
OUI version : 13.9.4.0.0
Running from : /u03/em24/middleware/oms_home
Log file location : /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/opatch2025-06-05_02-31-25AM_1.log
OMSPatcher log file: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/37629905/omspatcher_2025-06-05_02-31-44AM_analyze.log
Please enter OMS weblogic admin server URL(t3s://mk23ai-b:7102):>
Please enter OMS weblogic admin server username(weblogic):>
Please enter OMS weblogic admin server password:>
Enter SYS or Non-SYS (Admin User) username: sys
Enter 'sys' password :
Checking if current repository database is a supported version
Current repository database version is supported
Prereq "checkComponents" for patch 37616329 passed.
Prereq "checkComponents" for patch 37616365 passed.
Prereq "checkComponents" for patch 37616341 passed.
Prereq "checkComponents" for patch 37616358 passed
Prereq "checkComponents" for patch 37616336 passed.
Prereq "checkComponents" for patch 37616362 passed.
Prereq "checkComponents" for patch 37616375 passed.
Configuration Validation: Success
Running apply prerequisite checks for sub-patch(es) "37616375" and Oracle Home "/u03/em24/middleware/ext_oms_home"...
Sub-patch(es) "37616375" are successfully analyzed for Oracle Home "/u03/em24/middleware/ext_oms_home"
Running apply prerequisite checks for sub-patch(es) "37616362,37616329,37616358,37616341,37616336,37616365" and Oracle Home "/u03/em24/middleware/oms_home"...
Sub-patch(es) "37616362,37616329,37616358,37616341,37616336,37616365" are successfully analyzed for Oracle Home "/u03/em24/middleware/oms_home"
Complete Summary
================
All log file names referenced below can be accessed from the directory "/u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/2025-06-05_02-31-25AM_SystemPatch_37629905_1"
Prerequisites analysis summary:
-------------------------------
The following sub-patch(es) are applicable:
Featureset Sub-patches Log file
---------- ----------- --------
oracle.sysman.top.oms 37616362,37616329,37616358,37616341,37616336,37616365 37616362,37616329,37616358,37616341,37616336,37616365_opatch2025-06-05_02-35-33AM_2.log
oracle.sysman.top.zdt 37616375
37616375_opatch2025-06-05_02-35-19AM_2.log
The following sub-patches are not needed by any component installed in the OMS system:
37465809,37616360,37616345,37616371
Log file location: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/37629905/omspatcher_2025-06-05_02-31-44AM_analyze.log
OMSPatcher succeeded.
3. Installing the Release Update using a traditional patching method
3.1. Set the ORACLE_HOME to the location of the OMS home, and ensure the bin directory from the OMS home is included in the PATH environment variable:
$ export ORACLE_HOME=/u03/em24/middleware/oms_home
$ export PATH=$ORACLE_HOME/bin:$PATH
3.2. Shut down the OMS:
$ emctl stop oms
Oracle Enterprise Manager 24ai Release 1
Copyright (c) 1996, 2024 Oracle Corporation. All rights reserved.
Stopping Oracle Management Server...
Oracle Management Server Successfully Stopped
Oracle Management Server is Down
JVMD Engine is Down
3.3. Navigate to the patch 37629905 directory and run apply
$ cd 37629905
$ /u03/em24/middleware/oms_home/OMSPatcher/omspatcher apply ./
OMSPatcher Automation Tool
Copyright (c) 2024, Oracle Corporation. All rights reserved.
OMSPatcher version : 13.9.24.4.0
OUI version : 13.9.4.0.0
Running from : /u03/em24/middleware/oms_home
Log file location : /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/opatch2025-06-05_03-04-16AM_1.log
OMSPatcher log file: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/37629905/omspatcher_2025-06-05_03-04-37AM_apply.log
Please enter OMS weblogic admin server URL(t3s://mk23ai-b:7102):>
Please enter OMS weblogic admin server username(weblogic):>
Please enter OMS weblogic admin server password:>
Enter SYS or Non-SYS (Admin User) username: sys
Enter 'sys' password :
Checking if current repository database is a supported version
Current repository database version is supported
Prereq "checkComponents" for patch 37616329 passed.
Prereq "checkComponents" for patch 37616365 passed.
Prereq "checkComponents" for patch 37616341 passed.
Prereq "checkComponents" for patch 37616358 passed.
Prereq "checkComponents" for patch 37616336 passed.
Prereq "checkComponents" for patch 37616362 passed.
Prereq "checkComponents" for patch 37616375 passed.
Configuration Validation: Success
Running apply prerequisite checks for sub-patch(es) "37616375" and Oracle Home "/u03/em24/middleware/ext_oms_home"...
Sub-patch(es) "37616375" are successfully analyzed for Oracle Home "/u03/em24/middleware/ext_oms_home"
Running apply prerequisite checks for sub-patch(es) "37616362,37616329,37616358,37616341,37616336,37616365" and Oracle Home "/u03/em24/middleware/oms_home"...
Sub-patch(es) "37616362,37616329,37616358,37616341,37616336,37616365" are successfully analyzed for Oracle Home "/u03/em24/middleware/oms_home"
To continue, OMSPatcher will do the following:
[Patch and deploy artifacts] : Apply sub-patch(es) [ 37616329 37616336 37616341 37616358 37616362 37616365 37616375 ]
Apply sub-patch(es) [ 37616329 37616336 37616341 37616358 37616362 37616365 37616375 ]
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616329_May_13_2025_03_57_04/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/ext_oms_home/.omspatcher_storage/37616375_May_13_2025_05_14_54/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616365_May_13_2025_05_15_38/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616341_May_13_2025_05_15_15/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616358_May_13_2025_05_15_47/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616336_May_13_2025_05_16_05/original_patch";
Apply RCU artifact with patch "/u03/em24/middleware/oms_home/.omspatcher_storage/37616362_May_13_2025_05_16_27/original_patch";
Register MRS artifact "assoc";
Register MRS artifact "procedures";
Register MRS artifact "commands";
Register MRS artifact "omsPropertyDef";
Register MRS artifact "targetType";
Register MRS artifact "default_collection";
Register MRS artifact "jobTypes";
Register MRS artifact "systemStencil";
Register MRS artifact "discovery";
Register MRS artifact "EcmMetadataOnlyRegistration";
Register MRS artifact "namedQuery";
Register MRS artifact "storeTargetType";
Register MRS artifact "swlib";
Register MRS artifact "OracleCertifiedTemplate";
Register MRS artifact "TargetPrivilege";
Register MRS artifact "gccompliance";
Register MRS artifact "runbooks"
Do you want to proceed? [y|n]
y
Could not recognize input. Please re-enter.
y
User Responded with: Y
Stopping all the services on primary OMS.....
Please monitor log file: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/2025-06-05_03-29-16AM_SystemPatch_37629905_9/stop_oms_all_2025-06-05_03-29-16AM.log
Stopping the Central agent .....
Applying the one-off patch .....
Applying sub-patch(es) "37616329,37616336,37616341,37616358,37616362,37616365"
Please monitor log file: /u03/em24/middleware/oms_home/cfgtoollogs/opatch/opatch2025-06-05_03-39-19AM_4.log
Applying sub-patch(es) "37616375"
Please monitor log file: /u03/em24/middleware/ext_oms_home/cfgtoollogs/opatch/opatch2025-06-05_03-46-21AM_5.log
Starting the ADMIN .....
Please monitor log file: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/2025-06-05_03-46-50AM_SystemPatch_37629905_14/start_admin_2025-06-05_03-46-50AM.log
Configure API Gateway .....
Please monitor log file: /u03/em24/middleware/oms_home/cfgtoollogs/omspatcher/2025-06-05_03-48-17AM_SystemPatch_37629905_15/config_apigateway_2025-06-05_03-48-17AM.log
Registering the start OP ......
DB user 'sys' is allowed to perform startOP patching operation.
Update the patching flag .....
Updating repository with RCU reference file "/u03/em24/middleware/oms_home/.omspatcher_storage/37616329_May_13_2025_03_57_04/original_patch"
<This block has been intentionally secluded>
Registering service "jobTypes" with register file "/u03/em24/middleware/oms_home/plugins/oracle.sysman.db.oms.plugin_24.1.1.0.0/metadata/jobTypes/DGFileTransfer.xml" for plugin id as "oracle.sysman.db"...
...
Starting the central agent .....
Resetting the patching flag .....
Resetting the job queue process .....
The job_queue_processes parameter is set to 0 in the repository database. Resetting the job_queue_processes parameter to its original value 248 in the repository database to start the OMS.
Registering the end OP ......
DB user 'sys' is allowed to perform endOP patching operation.
Running the post apply sql .....
Starting the oms
...
Patching summary:
-----------------
Binaries of the following sub-patch(es) have been applied successfully:
Featureset Sub-patches Log file
---------- ----------- --------
oracle.sysman.top.zdt_24.1.0.0.0 37616375 37616375_opatch2025-06-05_03-46-21AM_5.log
oracle.sysman.top.oms_24.1.0.0.0 37616329,37616336,37616341,37616358,37616362,37616365 37616329,37616336,37616341,37616358,37616362,37616365_opatch2025-06-05_03-39-19AM_4.log
The following sub-patches are not needed by any component installed in the OMS system:
37465809,37616360,37616345,37616371
...
OMSPatcher succeeded
3.4. Make sure that omspatcher started OMS automatically, that is also visible from the above output (3.3 step):
$ export ORACLE_HOME=/u03/em24/middleware/oms_home
$ emctl status oms
WebTier is Up
Oracle Management Server is Up
JVMD Engine is Up
Otherwise, start it manually:
$ emctl start oms
4. Review the inventory to confirm the applied patch
$ export ORACLE_HOME=/u03/em24/middleware/oms_home
$ /u03/em24/middleware/oms_home/OMSPatcher/omspatcher lspatches