Reduction rxdrop/s – receive packet drops per second
May 1, 2025 Leave a comment
Note: The post may seem related to Linux only. However, the issue of high rxdrop/s affects anything, especially Oracle database performance, if it occurs on the database server.
In this post, I will explain the parameters that affect the behavior of receive packet drops per second (rxdrop/s).
The post is more about workarounds and tuning values rather than identifying exactly what has changed and why the fragmentation level has increased.
We will discuss several key /etc/sysctl.conf parameters that can help make fragmentation more manageable, these are:
net.ipv4.ipfrag_high_thresh = 67108864
net.ipv4.ipfrag_low_thresh = 66060288
net.ipv4.ipfrag_time = 10
Problem:
The ksar graph (a tool that interprets output from sar) was displaying peaks for interface errors on eth1 interface, particularly rxdrop/s:
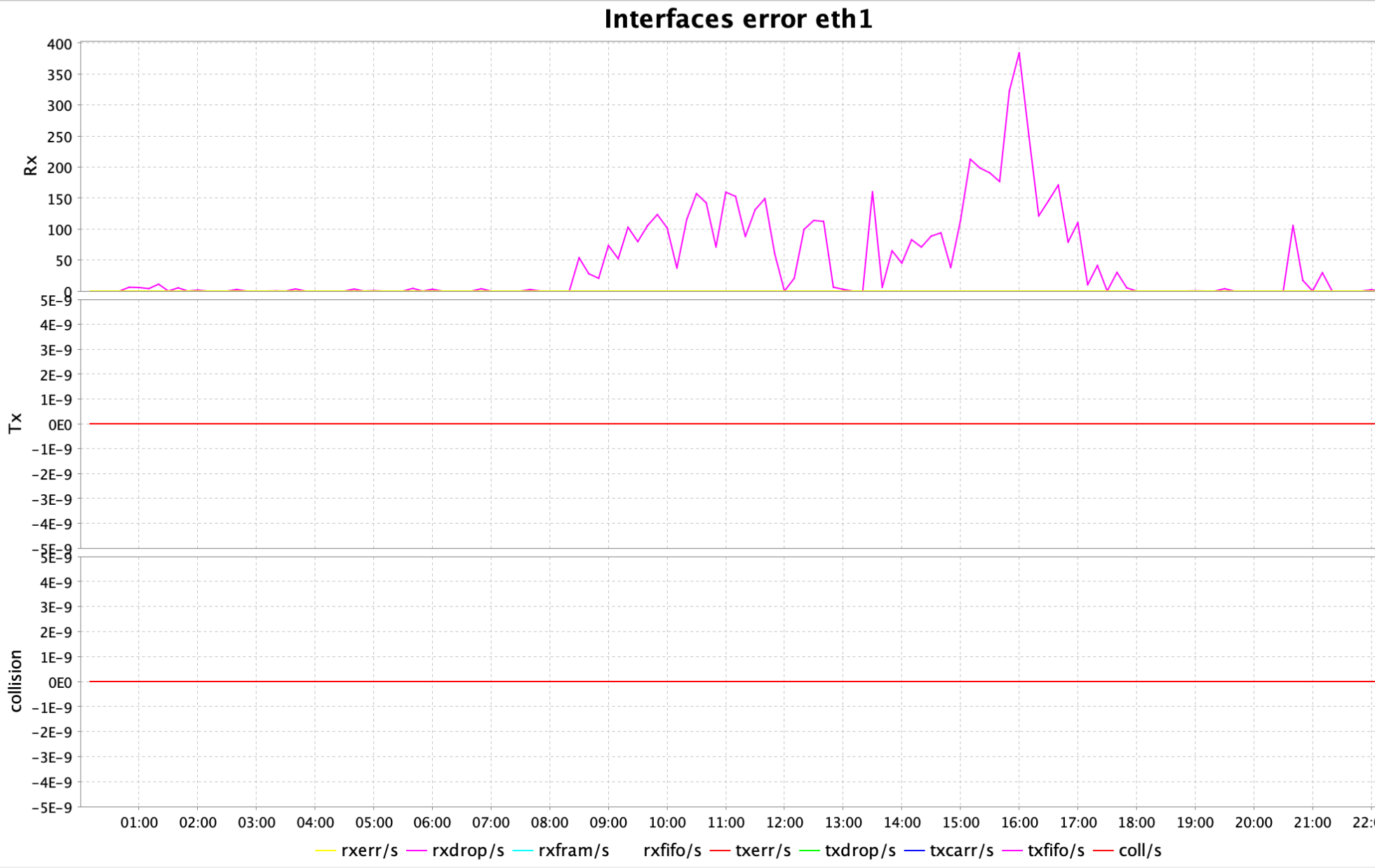
Workaround:
The following kernel parameters in Linux control how the system handles IP packet fragments in the IPv4 stack.
- The maximum memory threshold (in bytes) that the kernel can use to store IPv4 fragmented packets:
net.ipv4.ipfrag_high_thresh = 67108864
When the total memory used for IP fragments exceeds 64 MB (67108864), the kernel will start dropping fragments until memory usage falls below the low threshold (ipfrag_low_thresh next parameter).
- The minimum memory threshold to stop dropping fragments:
net.ipv4.ipfrag_low_thresh = 66060288
Once memory drops below ~63 MB (66060288), fragment discarding stops.
- The time (in seconds) the kernel will keep an incomplete, fragmented packet in memory before discarding it:
net.ipv4.ipfrag_time = 10
The default is often 30 seconds. Here it’s reduced to 10 seconds.
This helps prevent memory from being held too long by incomplete or malicious fragment streams, which are common in DoS attacks.
After changing these parameters in /etc/sysctl.conf you need to run sysctl -p to apply the modified kernel parameters and make them effective at runtime.
