Resize ASM disks in GCP (FG enabled cluster)
July 20, 2020 Leave a comment
Increasing disks in GCP is an online procedure and you don’t have to stop the VM.
1. If the node is a database node, stop all local database instances running on the node.
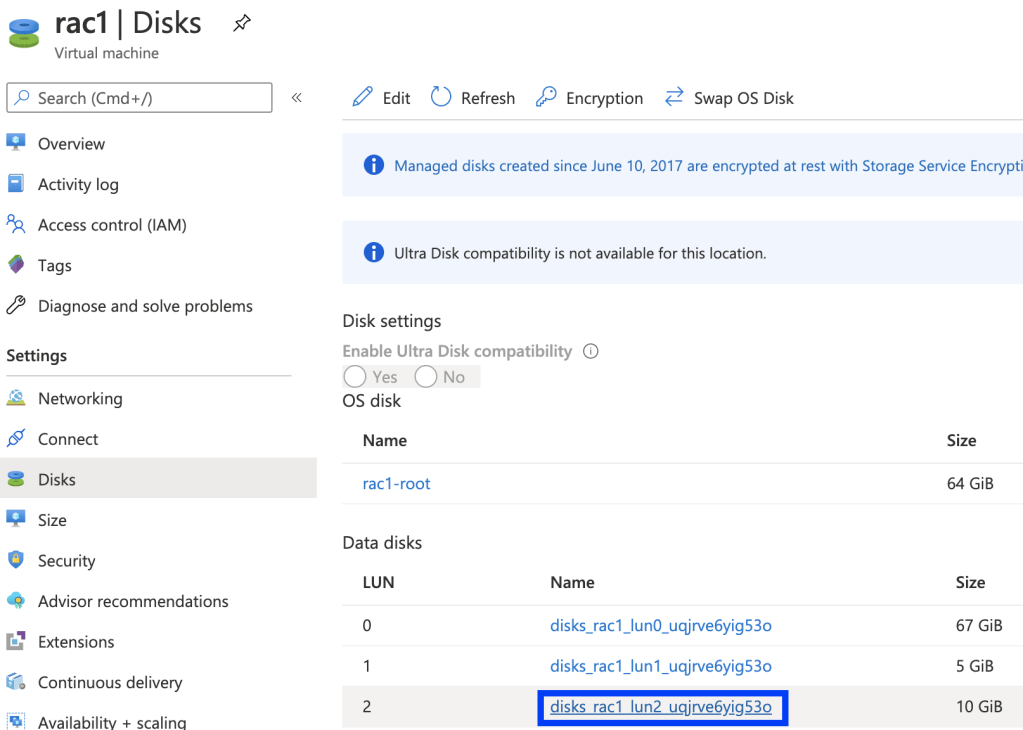
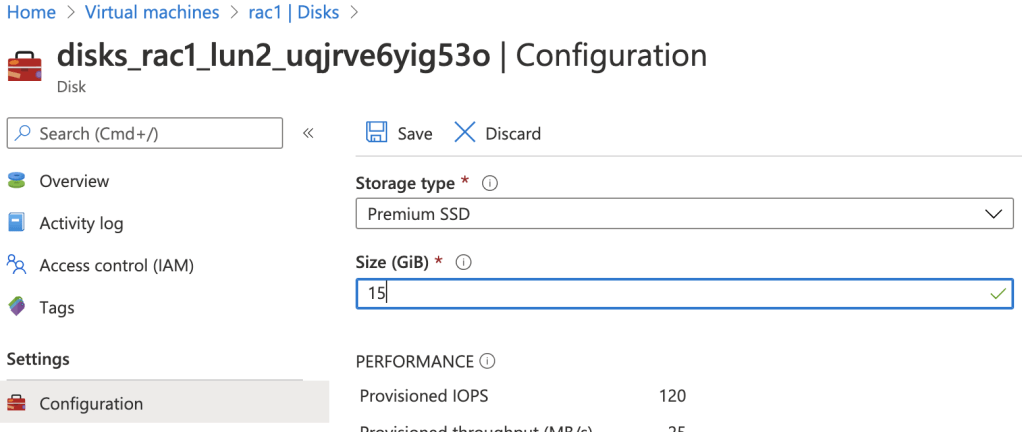
2. Go to the Disks page -> click the name of the disk that you want to resize -> click Edit -> enter the new size in Size field -> Save.
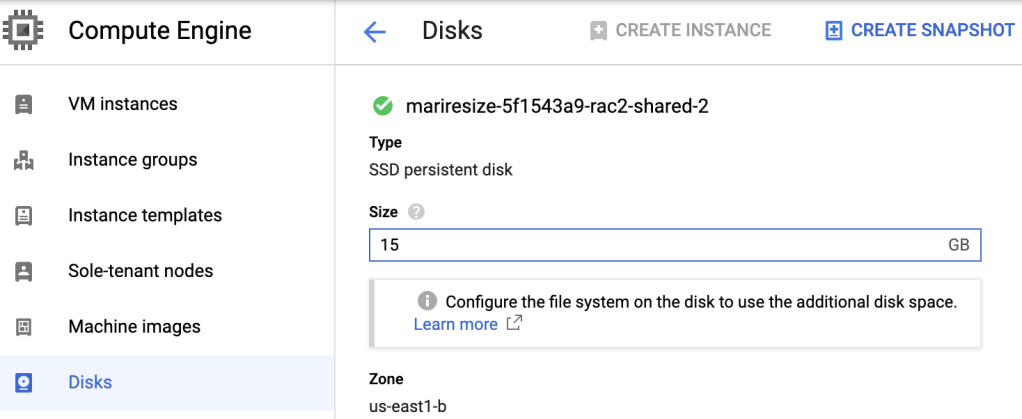
Please note that all data disks (not quorum disk) must be increased under the same diskgroup, otherwise ASM will not let you to have different sized disks.
Choose another data disks and repeat the same steps.
3. Run the following on database nodes via root user:
# for i in /sys/block/*/device/rescan; do echo 1 > $i; done
4. Check new disk sizes:
If it is Fg cluster, Phys_GiB column must show increased size:
[root@rac1 ~]# flashgrid-dg show -G DATA
...
------------------------------------------------------------
FailGroup ASM_Disk_Name Drive Phys_GiB ASM_GiB Status
------------------------------------------------------------
RAC1 RAC1$SHARED_2 /dev/flashgrid/rac1.shared-2 15 10 ONLINE
RAC2 RAC2$SHARED_2 /dev/flashgrid/rac2.shared-2 15 10 ONLINE
RACQ RACQ$SHARED_3 /dev/flashgrid/racq.shared-3 1 1 ONLINE
------------------------------------------------------------
In case it is a normal cluster, OS_MB must show increased size:
# su - grid
$ sqlplus / as sysasm
SQL> select TOTAL_MB/1024,OS_MB/1024 from v$asm_disk where GROUP_NUMBER=2;
TOTAL_MB/1024 OS_MB/1024
------------- ----------
10 15
10 15
1 1
5. Connect to the ASM from any database node and run:
# su - grid
$ sqlplus / as sysasm
SQL> ALTER DISKGROUP DATA RESIZE ALL;
The above command will resize all disks in the specified diskgroup based on their size returned by OS.
6. Check new sizes:
Fg cluster:
[root@rac1 ~]# flashgrid-dg show -G DATA
...
------------------------------------------------------------
RAC1 RAC1$SHARED_2 /dev/flashgrid/rac1.shared-2 15 15 ONLINE
RAC2 RAC2$SHARED_2 /dev/flashgrid/rac2.shared-2 15 15 ONLINE
RACQ RACQ$SHARED_3 /dev/flashgrid/racq.shared-3 1 1 ONLINE
------------------------------------------------------------
Normal cluster:
SQL> select TOTAL_MB/1024,OS_MB/1024 from v$asm_disk where GROUP_NUMBER=2 ;
TOTAL_MB/1024 OS_MB/1024
------------- ----------
15 15
15 15
1 1
Phys_GiB and ASM_GiB should have the same increased size, which means disks are resized and you can use extended space.